LaTeX 渲染有问题。将就着看吧。
# 第一讲 计算机系统概述
# 组织与结构
许多计算机制造商提供了一系列的计算机模型,它们都具有相同的体系结构,但组成不同。
一台机器是否具备乘法指令的功能,这是计算机体系结构的问题
如何实现这个乘法指令的,使用专门的乘法电路还是采用连续相加的加法电路等,这是计算机组成的问题
组织:对编程人员不可见。可以理解为具体功能实现的过程。
结构:对编程人员可见。理解为有哪些功能、指令等。
# 指令集体系结构 ISA
ISA 是一种规约(Specification),它规定了如何使用硬件。
在通用计算机系统是必不可少的一个抽象层。
# 摩尔定律
当价格不变时,单芯片上所能包含的晶体管数量每年翻一番(后来变成每 18 个月翻一番)
# 冯诺依曼结构
三个基本原则:
二进制
存储程序
5 个组成部分
主存储器:地址和存储的内容
算术逻辑单元 / 处理单元 ALU:执行信息的实际处理
程序控制单元 / 控制单元 PC:指挥信息的处理
输入设备:将信息送入计算机中
输出设备:将处理结果以某种形式显示在计算机外
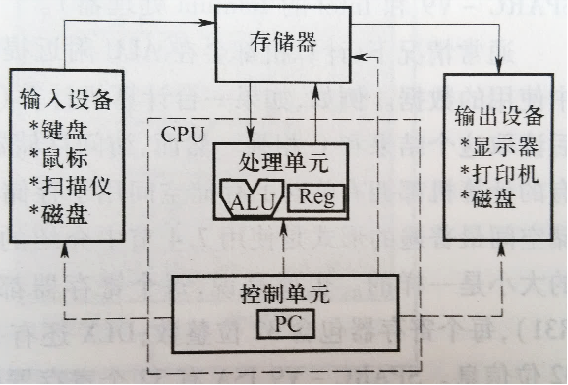
内存是存储器;硬盘是输入输出设备
冯・诺伊曼的最重要的思想是 “存储程序(Stored-program)”
# 计算机性能
计算机设计的主要目标是:提高 CPU 性能
# CPU 性能
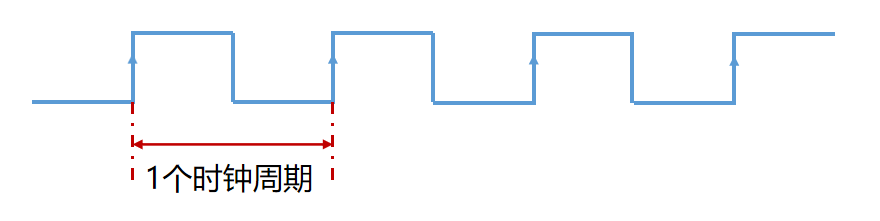
时钟频率 f / 时钟速度(单位:Hz)
计算机在单位时间内(例如 1 秒钟)执行最基本操作的次数
时钟周期 t / 周期时间(单位:s)
执行每次最基本操作的时间
时钟周期是时钟频率的倒数。t = \frac{1}
周期时间即为两个电子脉冲之间的时间
![5cdbdfaa3d2dd5de4fc26e60ddfa85da.png]()
CPI(Cycles Per Instruction)每条指令所要的时钟周期数
也可以理解为每条指令所需要的基本操作的次数
![a34a2ef067e6aa328287a4b89b208c61.png]()
整个 CPI,即平均每条指令所需要的时钟周期数,用总时钟周期数除以总指令数即可。总时钟周期数,通过把不同种指令总时钟周期数相加得到。
一个程序的处理时间:,即总时钟周期数乘以单个时钟周期的时间。
MIPS (Million Instructions Per Second)每秒百万条指令
MIPS 表示 CPU 每秒钟可以执行多少百万条指令。
![e442eb966ae7e0a184cde9e08b6250f4.png]()
首先计算每秒执行多少条指令。即用总指令条数除以总时间(单位 s)。接着换算成每秒执行多少百万条指令。即再除以 。
由于 ,因此公式也可换成后面那种形式。
MFLOPS(Million Floating Point Operations Per Second)百万浮点运算每秒
![f8ae9a6c07156135f3e565d5c22d74f9.png]()
![5151377bbc7473a7a335e883b1771980.png]()
CPU 性能的基准程序
使用一系列基准程序来测量系统的性能
![f3f2daeb6b07bfa5c36457a5515d3df9.png]()

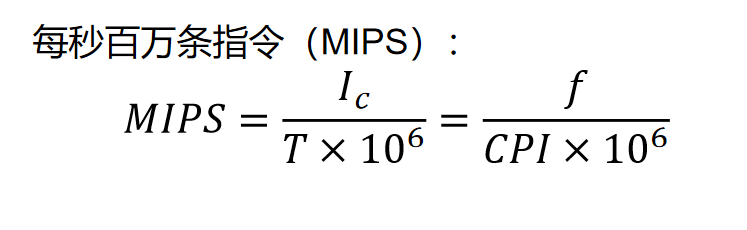



# 性能设计的基本原则
Amdahl 定律
加快某部件执行速度所获得的系统性能加速比,受限于该部件在系统中所占的重要性比例
性能增加的递减规则:如果仅仅对计算机中的一部分做性能改进,改进越多,系统获得的效果越小。
# 计算机顶层结构
# CPU
中央处理单元(Central Processing Unit, CPU): 获取并执行指令的计算机组成部分,它由 ** 一个 ALU、一个控制单元(PC)和多个寄存器(Reg)** 构成。在单处理单元系统中,它通常简称为处理器。
# 存储器
在本门课及相关作业中,主存不等同于内存,因为准确来说,内部存储器确实不止包括主存。另外,从两本教材的整体术语使用情况来看,通常还是采用更准确的表述,即 “主存”。
主存(主存储器)是内存(内部存储器)的一部分。
内部存储器(内存)包含寄存器、高速缓存和主存。
# 第二讲 数据的机器级表示
# 整数
正数原码反码补码都一样。
负数:以 -8 为例
原码:10001000 最高位代表是负数。其余正常
反码:11110111 除了最高位外其他位取反
补码:11111000 反码+1
一个负数的补码等于将对应正数补码 各位取反、末位加一
# 移码表示
将每一个数值加上一个偏置常数(excess/bias)
通常当编码位数为 n 时,bias 取 或

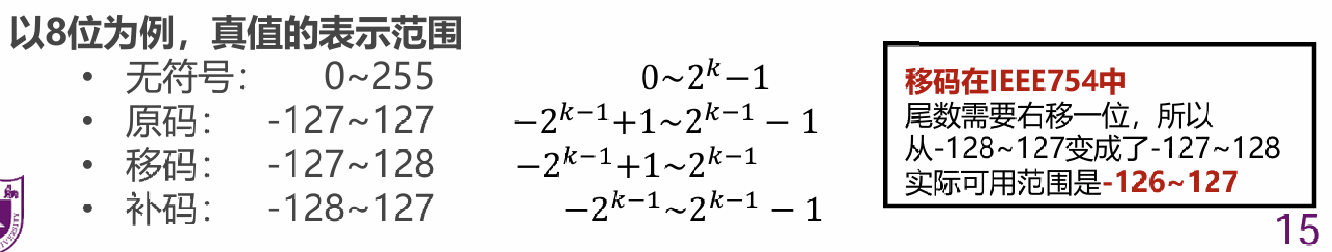
差别在于原码里 0 有两种表示方式,因此范围少了 1.
# 浮点数
# 规格化数
顺序:SEM(因为比较大小,按这个顺序最快)

# IEEE 754 标准

E 为无符号,计算出的值减去 127 得到阶码(规格化情况)。

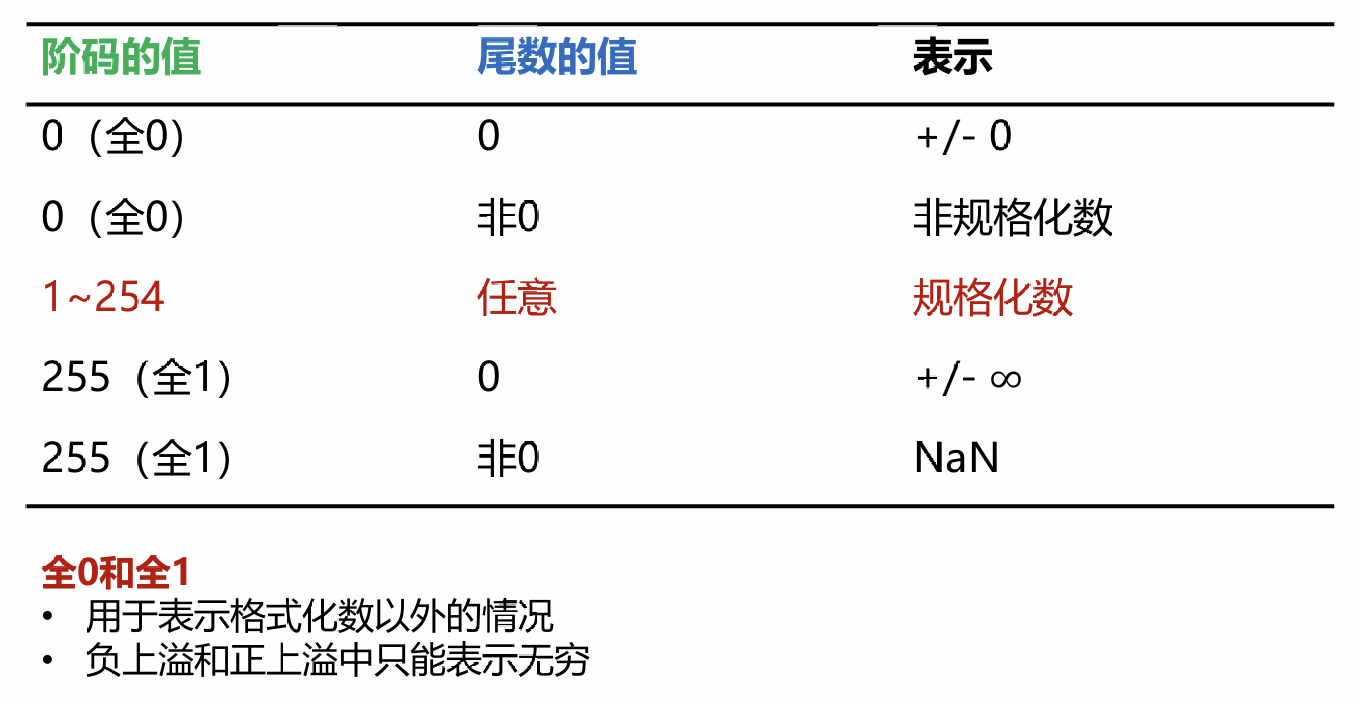
非规格化数,隐藏位为 0,阶码设为 - 126.
# NBCD 码

前四位为符号位。1100 为正,1101 为负。
# 补充:int 与 float 精度
float 能表示更大的数
靠近 0,float 精度更大
数字越大,int 精度越大
当 e = 23 时,int 与 float 精度相似。大于 23 后,int 精度更大。
# 第三讲 整数运算
# 加法器
与门延迟: 1 级门延迟 (1ty)
或门延迟: 1 级门延迟 (1ty)
异或门延迟: 3 级门延迟 (3ty)
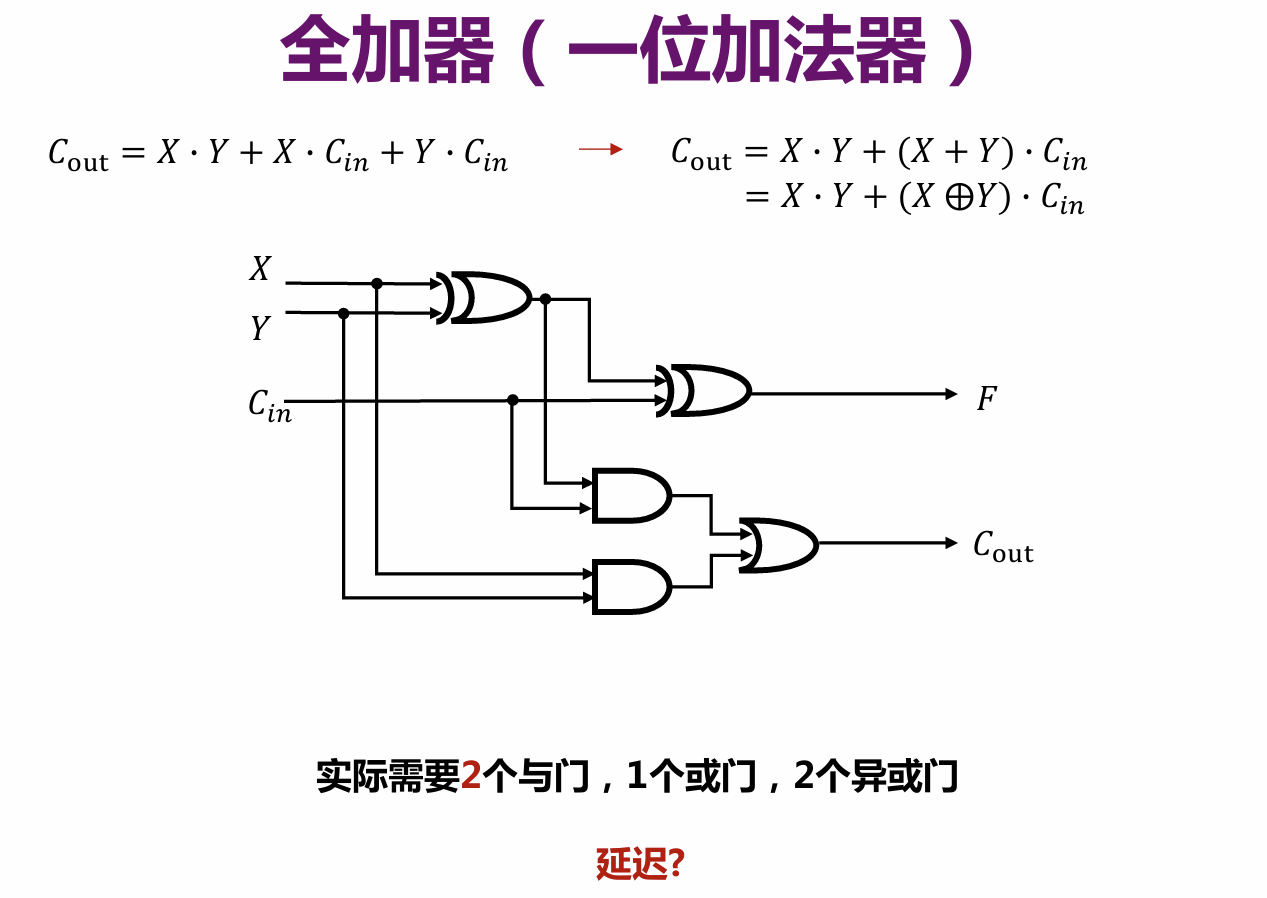
F:6ty,Cout:5ty(上面那个带一个弧的是异或门)
F 是和,C 是进位
# 全先行进位加法器
高位的运算必须等待低位的 “进位输出信号” 能否提前计算出 “进位输出信号”?—— 使用全先行进位加法器
延迟:1ty + 2ty + 3ty = 6ty
延迟和加法器的位数无关
# 补码表示的整数运算:加法,减法
如何判断溢出?若两个符号不同的数字相加,不会溢出。
若同号数字相加后变号,则溢出。
减法:将一方变为相反数后进行加法。溢出同理判断。
# 补码表示的整数运算:乘法
布斯乘法略
溢出:
硬件不判断溢出:寄存器会存 2n 位乘积
软件判断溢出:1)编译器判断溢出;2)程序员通过高级语言判断溢出
# 补码表示的整数运算:除法

# 恢复余数除法
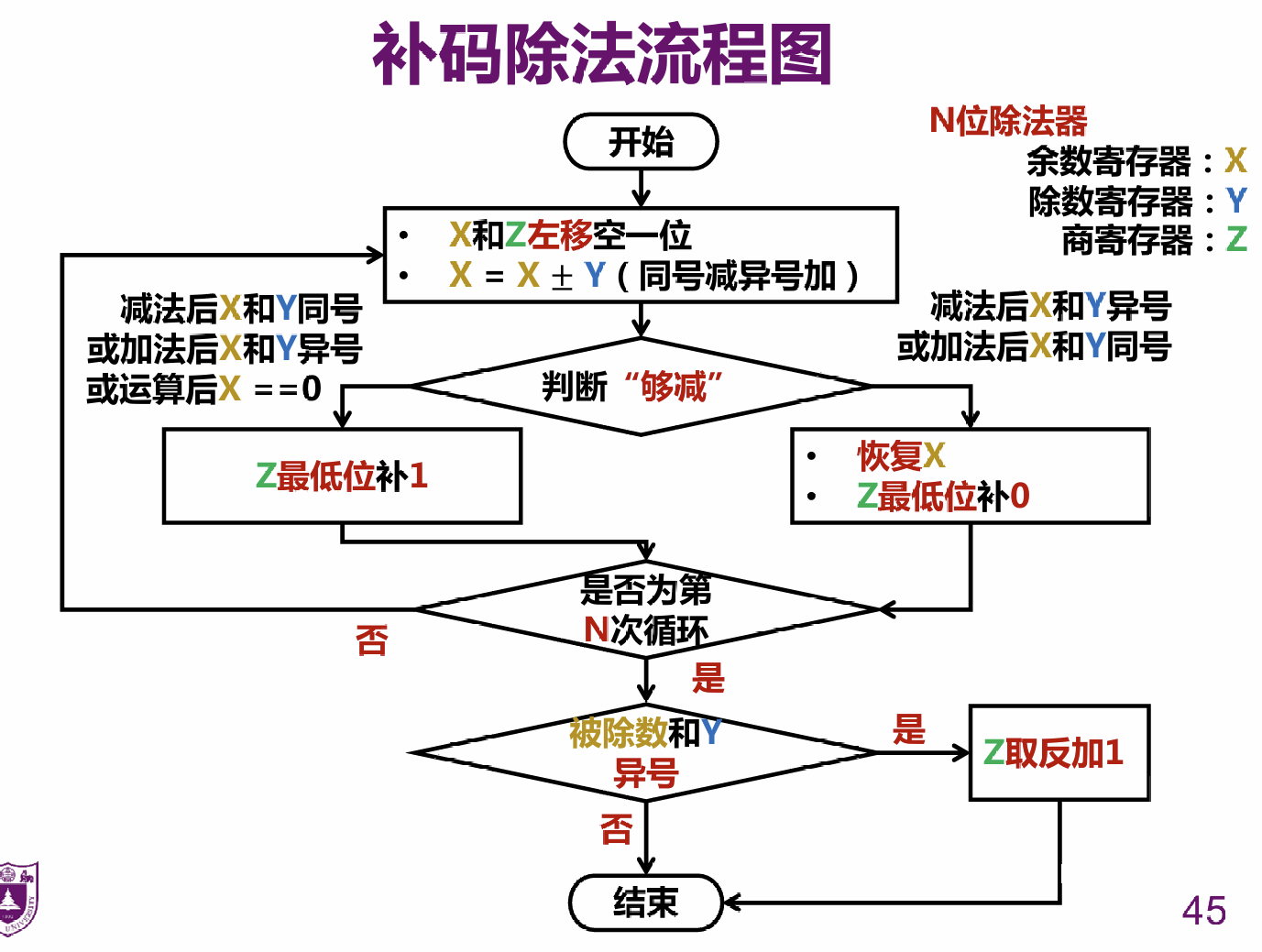
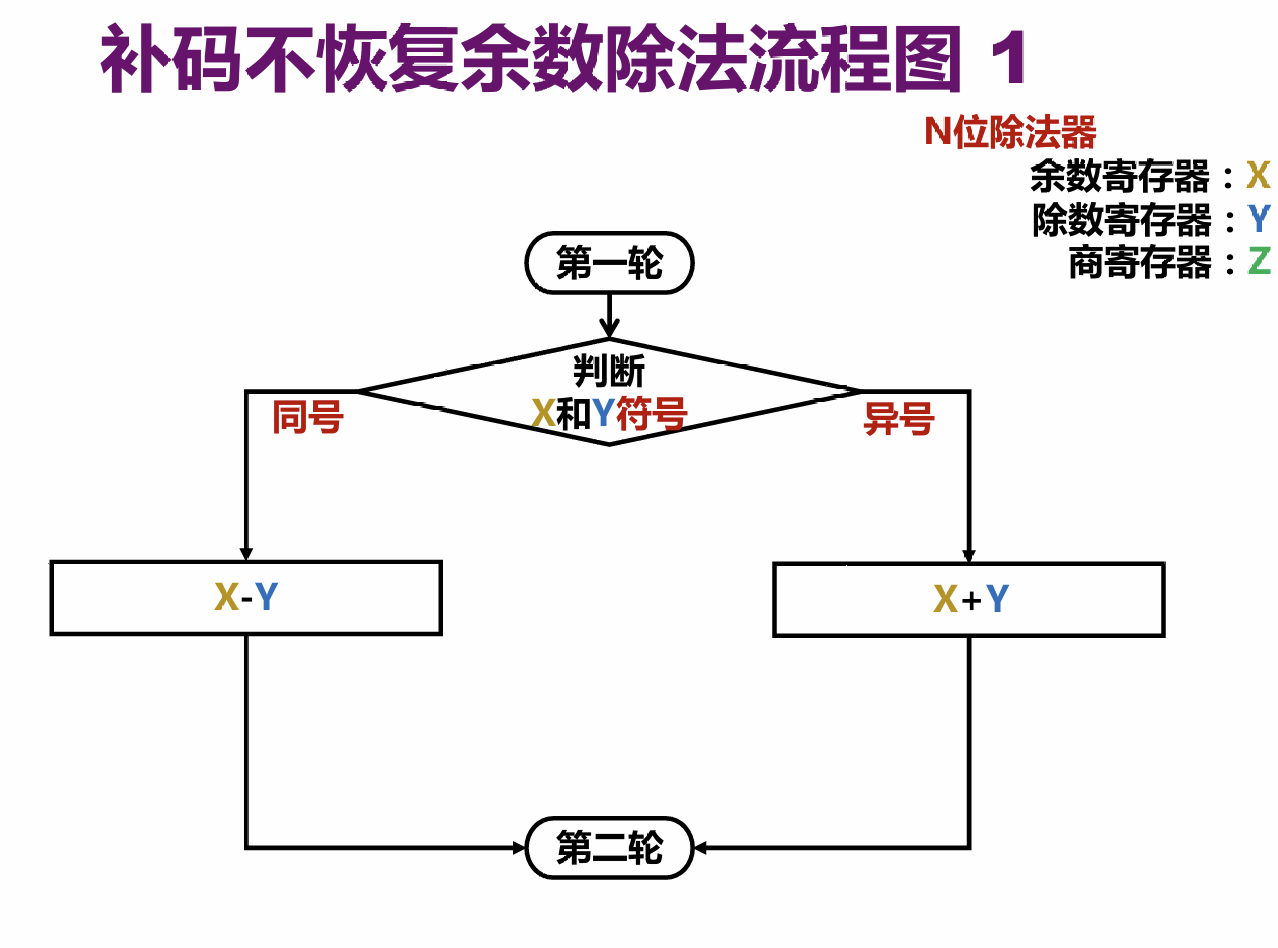
# 不恢复余数除法
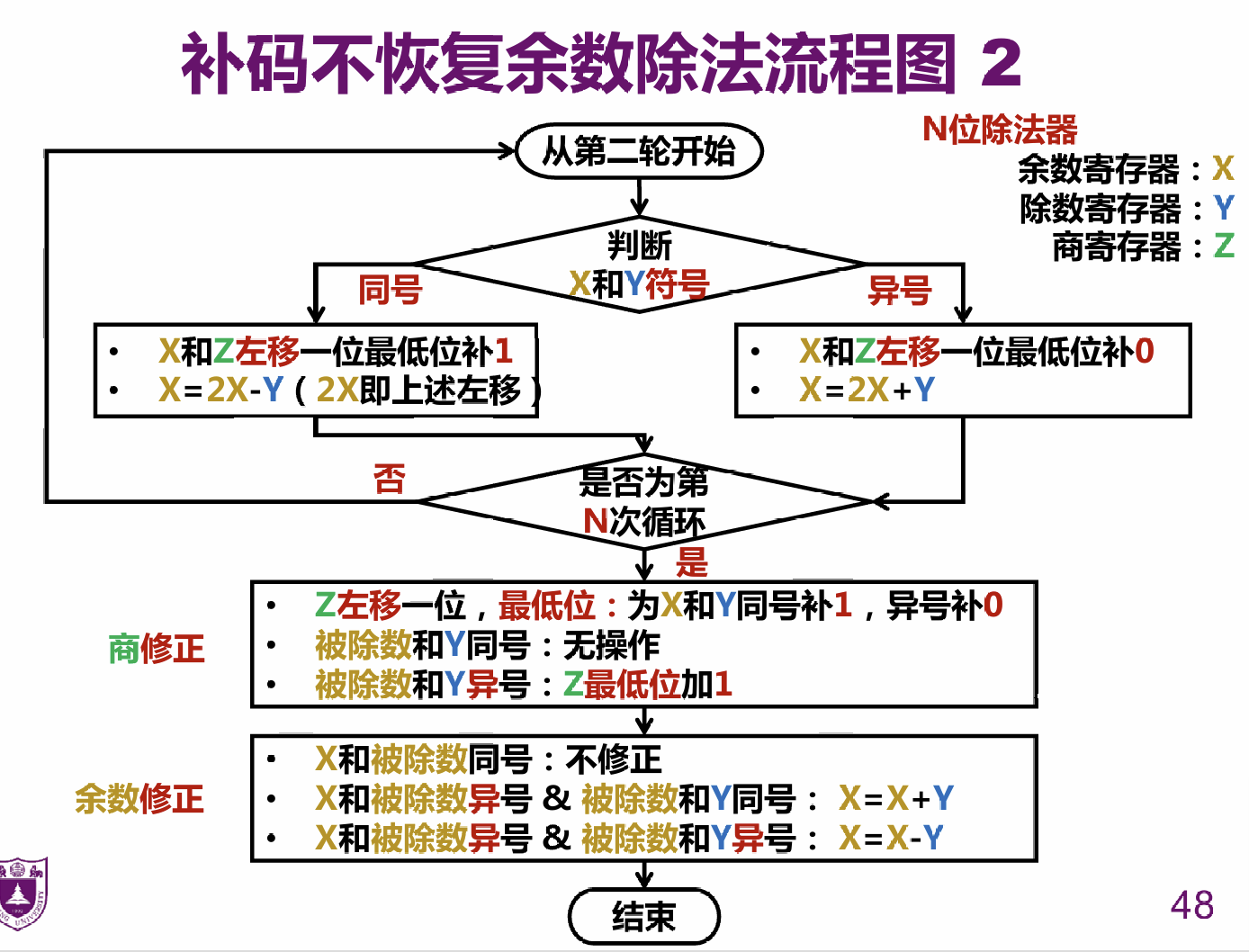
# 第四讲 浮点数运算
# 加法和减法
必须确保两个操作数具有相同的指数值(阶)
低阶向高阶对齐。
最后规格化
# 乘法和除法
阶码相加减
尾数相乘除
最后规格化结果
# 精度考虑:数据类型

GPT 解释
下面逐条解释图中的判断及其恒真性:
# 1.
X == (int)(float)X(恒假)X是int类型,(float)X将X转换为float类型,可能会引入精度损失(例如,对于某些较大的int值,float无法精确表示它们)。再将
(float)X转换回int时,如果由于精度损失导致值变化,则恒假。示例:
X = 2147483647(int的最大值),转换为float会失去精度,导致最终结果不等。
# 2.
X == (int)(double)X(恒真)X是int类型,(double)X将X转换为更高精度的double类型,double能精确表示int范围内的所有值。再将
(double)X转回int时,值不会发生变化,因此恒真。
# 3.
F == (float)(double)F(恒真)F是float类型,(double)F将其转换为更高精度的double类型,再将其转换回float。虽然
double有更高精度,但转换为double并不会改变float原本的值。最后转换回
float时,值也不会发生变化,因此恒真。
# 4.
D == (float)D(恒假)D是double类型,(float)D将其转换为精度较低的float类型,可能导致精度损失。如果
D中包含无法用float精确表示的值(如小数点后的更多有效数字或较大的数值),则转换后会产生误差,导致不相等。
# 5.
X == (float)X(恒假)X是int类型,(float)X将其转换为浮点数类型。float表示的整数值可能因精度限制出现误差,特别是在较大的整数时。示例:
X = 16777217(float的精度极限之外的值),此时(float)X将近似为16777216,导致不相等。
# 6.
X * X >= 0(恒假)对于
int类型,X * X的结果应该始终非负。然而,
int的乘法可能溢出,导致结果变为负数。示例:
X = 46341,则X * X = 2147488281(溢出为负数)。
# 7.
F * F >= 0(恒真)浮点数
F的平方恒为非负,因为:若
F为正或零,F * F结果为正或零。若
F为负,F * F结果仍为正。唯一特殊值是
NaN(Not-a-Number),但在比较中不会返回true。
# 8.
(D + F) - D == F(恒假)D是double类型,F是float类型,D + F会将F转换为double后再计算。由于
F转换为double可能存在精度误差,结果中的(D + F) - D可能与F不完全相等。示例:
D = 1.000000000000001,F = 1.0,此时D + F会有误差。
# 9.
(D + F) - F == D(恒假)- 类似于第 8 条,
F转换为double后可能失去部分精度,因此(D + F) - F可能与D不完全相等。
# 10.
1/3 == 1/3.0(恒假)1/3是整除操作,结果为0(因为两个整数相除,结果仍为整数)。1/3.0是浮点数除法,结果为0.3333...(近似值)。因为
0不等于0.3333...,所以恒假。
# 总结
这张图主要考察了类型转换和数值精度的问题,包括整数与浮点数之间的转换、浮点数的精度损失、以及溢出等特性。理解这些需要熟悉数据类型的表示和计算机的浮点数运算规则。
# 精度考虑:附加位与舍入
两位附加位
IEEE754 规定:中间结果须在右边加 2 个附加位(Guard & Round)
・保护位(Guard):在尾数右边的位,左规时被移到尾数中
・舍入位(Round):在保护位右边的位,作为舍入的依据
舍入方法(四种):
向最近 (看保护位首位是 0 还是 1 各占一半 1 进 0 舍)
向正无穷
向负无穷
向 0

# 第六讲 内部存储器
存储器(Memory)由一定数量的单元构成,每个单元可以被唯一标识,每个单元都 有存储一个数值的能力
地址:单元的唯一标识符(采用二进制)
地址空间:可唯一标识的单元总数
寻址能力:存储在每个单元中的信息的位数,即内存中能被单独识别并独立存放一个数据的最小内存空间
- 大多数存储器是字节(8bit)寻址的,32 位计算机的最大寻址空间(地址空间)为 4GB ($ 2^32} B = 2KB = 2^{12}MB = 4GB$)
# 层次结构
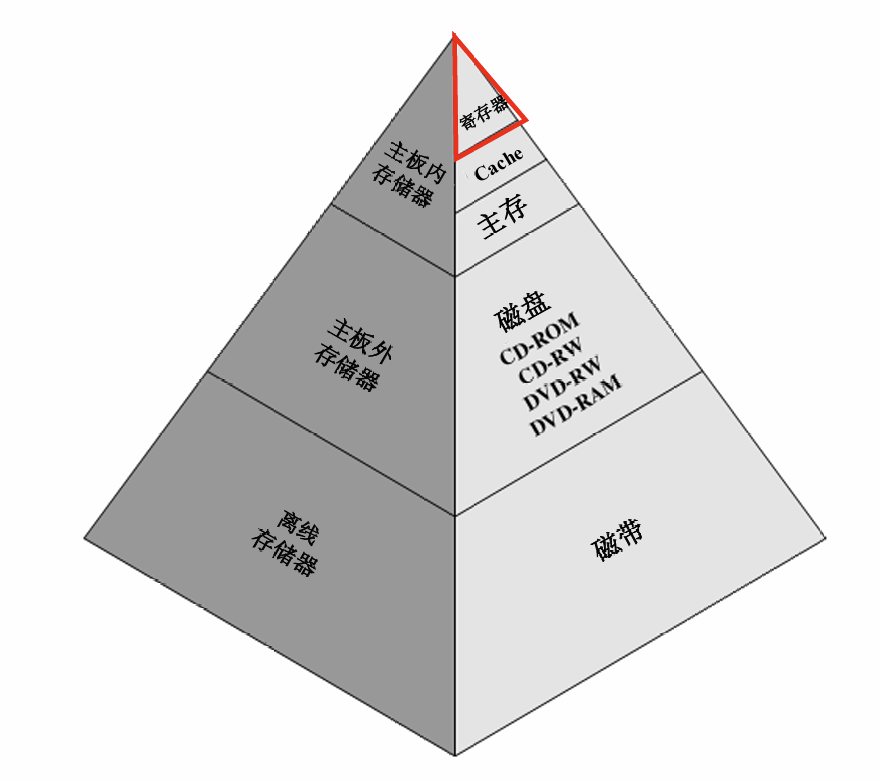
越上面的越靠近 cpu,存储空间越小,但速度越快
# 半导体存储器
用半导体芯片作主存储器是目前的主流做法
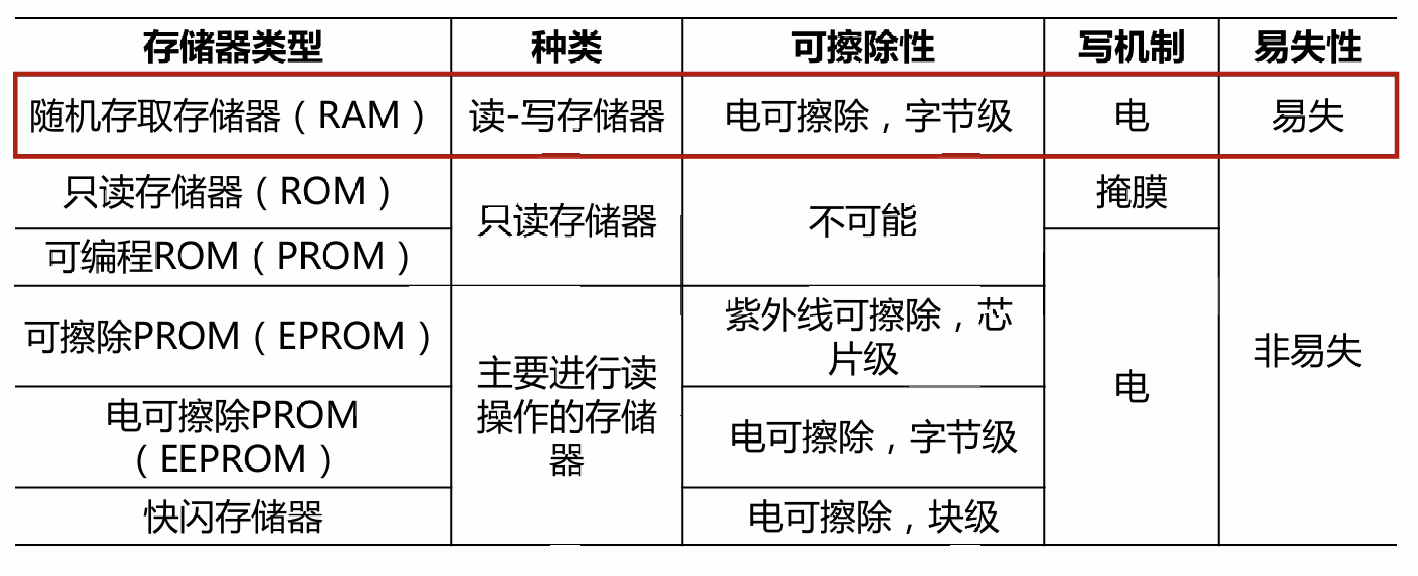
# RAM 随机存取存储器
随机访问:对存储器中任意数据的访问所花费的时间与数据所在位置无关
可以简单快速地进行读 / 写操作
易失的(Volatile)
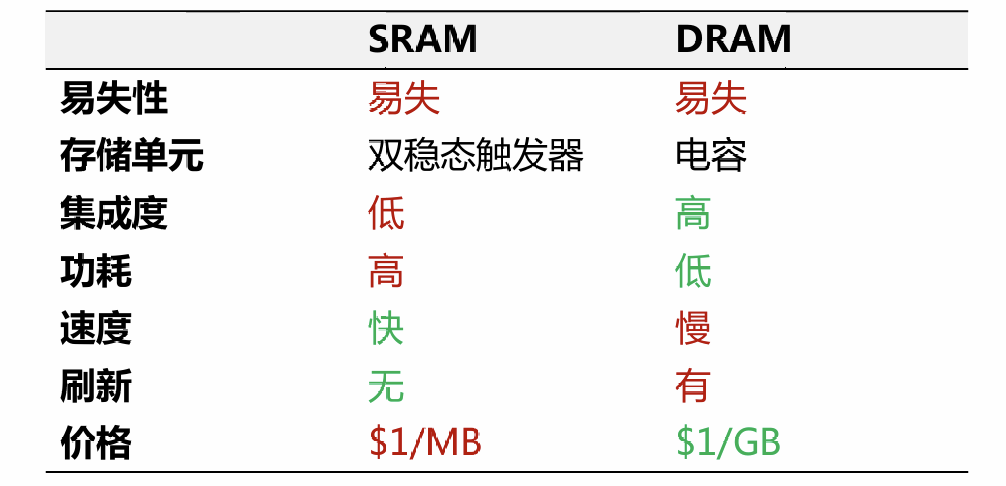
类型:
SRAM 静态 RAM
DRAM 动态 RAM
SRAM 比 DRAM 更快,但加价格也更高
# ROM 只读存储器
一种可以长期保存信息的存储器,具有断电后信息仍可继续保存的特点,在正常工作时只可读取数据,而不能写入数据
# PROM 可编程 ROM
只能被写入一次,其他和 ROM 相同
写过程是用电信号执行
以下是主要进行读操作的存储器:
# EPROM 光可擦除 / 可编程只读存储器
电写入(1->0)
光擦除(0->1)在写操作前将封装芯片暴露在紫外线下
# EEPROM 电可擦除 / 可编程只读存储器
电写入(1->0)
电擦除(0->1)
最贵
# Flash memory 快闪存储器
电可擦除:与 EEPROM 原理类似,优于 EPROM
可以在块级擦除,不能在字节级擦除:优于 EPROM,不如 EEPROM
需要先擦除再写入
# 寻址
位元(memory cell):半导体存储器的基本元件,用于存储 1 位数据
寻址单元:由若干相同地址的位元组成
# 地址译码器
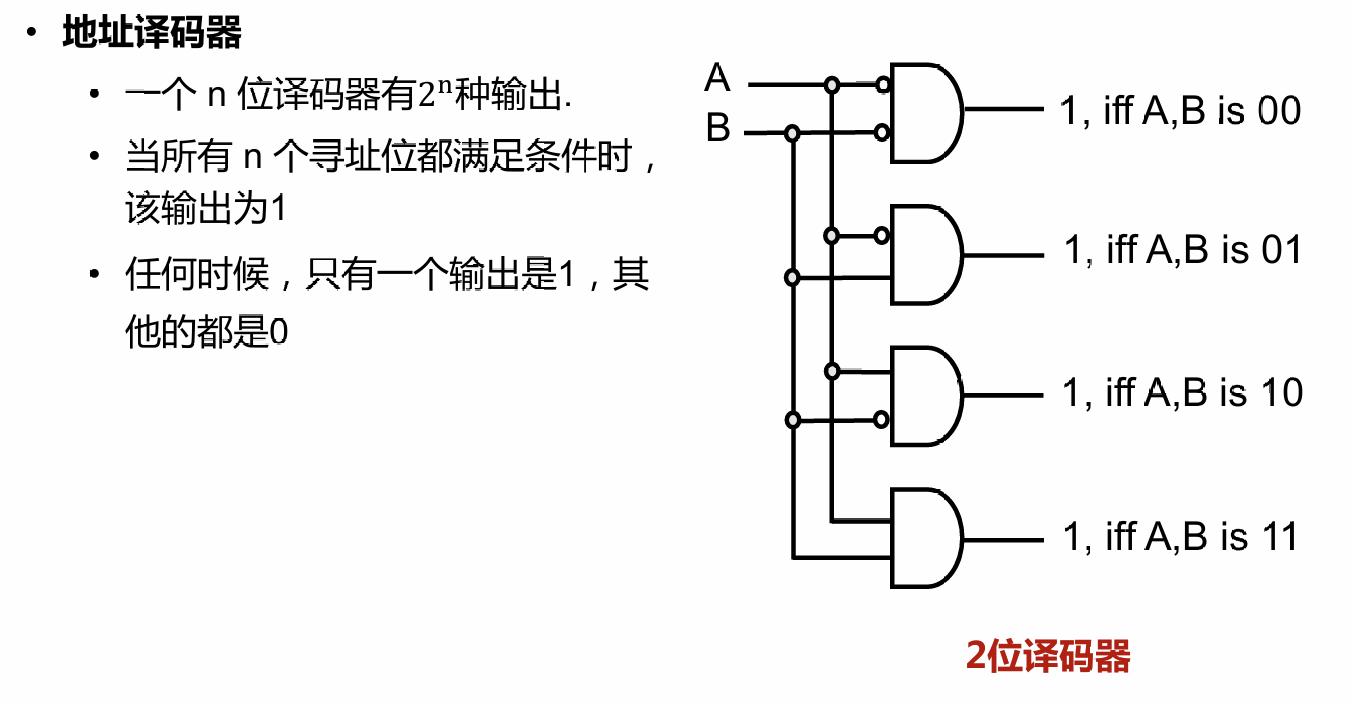
如何寻址:行访问,列访问
# 刷新
约束:刷新会占用片选线、地址线、地址译码器
集中式刷新
停止读写操作,并逐行刷新
刷新时无法操作内存(死区)
分散式刷新
在每个存储周期中,当读写操作完成时进行刷新
一次读写刷新一行,逐行刷新
会增加每个存储周期的时间
异步刷新
每一行各自以固定间隔(小于最大刷新周期,毫秒级)刷新
将 DRAM 的刷新安排在 CPU 对指令的译码阶段,可有效避免死区
效率高:常用
# DRAM 架构
传统 DRAM 是异步的。频率通常不超过 66MHz
高级 DRAM 架构是同步的。
同步 DRAM(Synchronous DRAM, SDRAM):频率通常不超过 133MHz
双速率 SDRAM(Double-Data-Rate SDRAM,DDR SDRAM / DDR):
DDR5 频率可达 4800MHz
# DDR SDRAM
实际上也是动态 RAM 的一种吧。
Double Data Rate:每个时钟周期发送两次数据,一次在时钟脉冲的上升沿,一次在下降沿
# 从位元到主存
位元→寻址单元→存储阵列→芯片→模块组织→主存
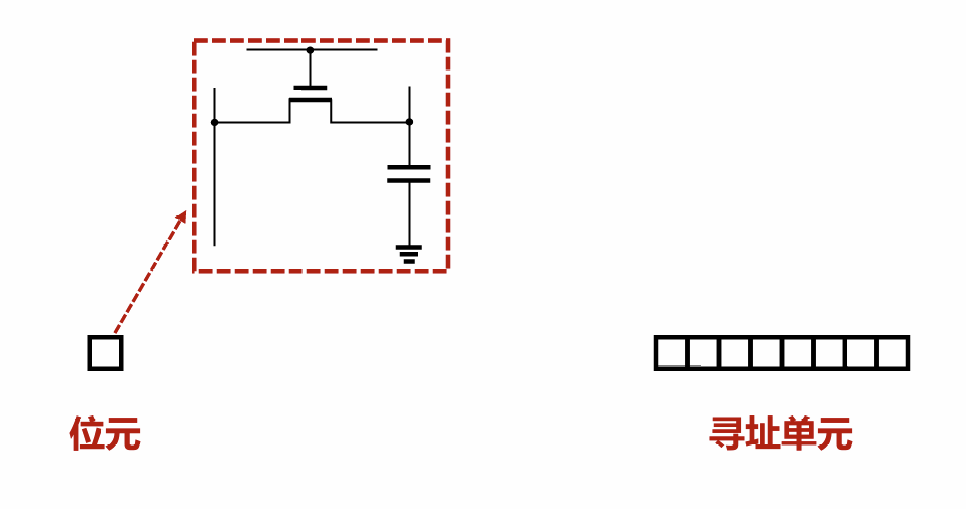
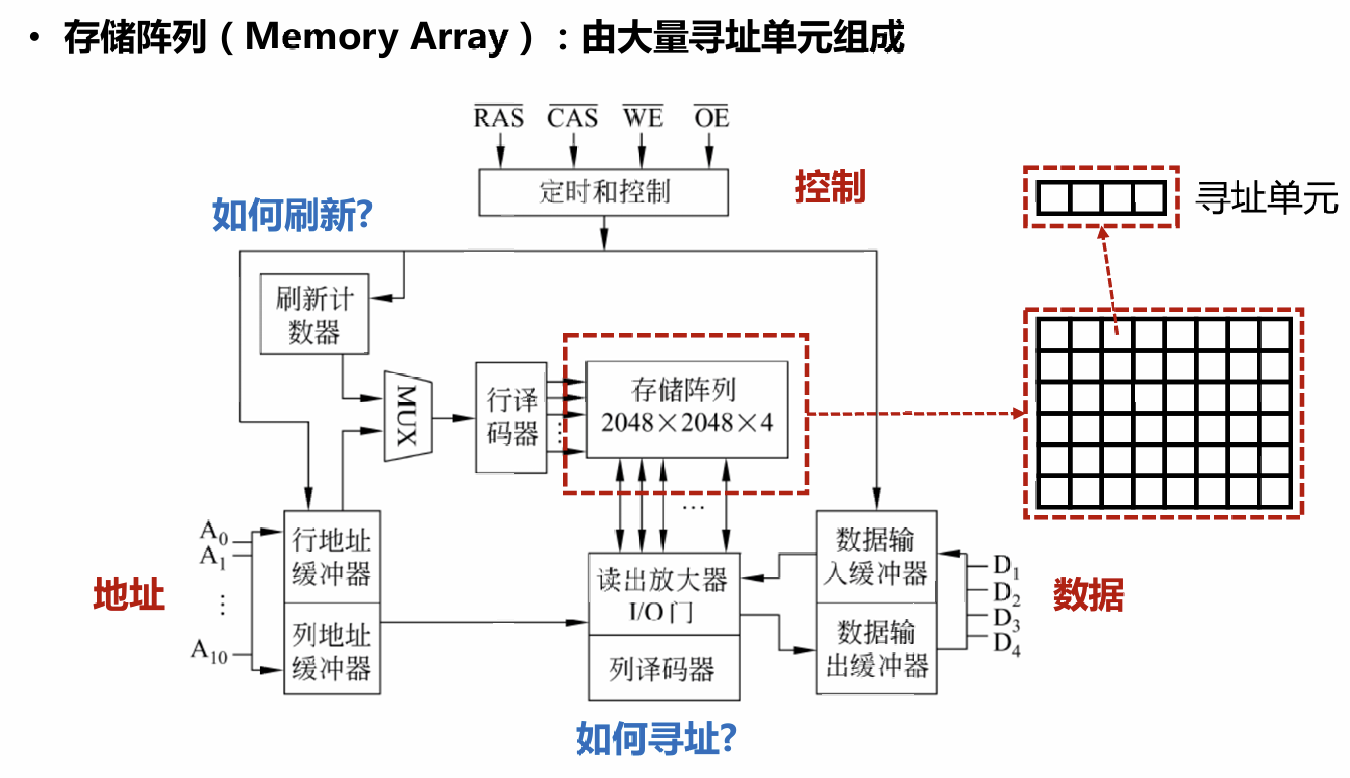
模块组织
位扩展:地址线不变,数据线增加
使用 8 块 4K×1 bit 的芯片组成 4K×8 bit 的存储器
即一个单元内存储数增加了
字扩展:地址线增加,数据线不变
使用 4 个 16K×8 bit 的芯片组成 64K×8 bit 的存储器
即增加了单元数
字、位同时扩展:地址线增加,数据线增加
- 使用 8 个 16K×4 bit 的芯片组成 64K×8 bit 的存储器